
Topology Visibility in Virtualized Environments
23 Jan 2015In a previous post i mentioned that there are many new challenges in SDN to achieve sufficient operations and management visibility.
In this post i am going to tackle one of the basic use case, finding all the physical paths between two virtual machines in our data center, mainly including the physical devices connecting the two hosts these virtual machines reside in (the case of two virtual machines in the same host is easy).
First, why i say all paths ? because in a common deployment today there is always load balancing and multi pathing on the way, usually with dynamic protocols that enable traffic to traverse in all possible paths, meaning we need to find all these paths. We will soon see that this makes our task more challenging.
Secondly, why being able to find the physical path between two VM’s is important? because when things go wrong we need to do root cause analysis and correlate the possible network deficiencies/outage in the VM to the physical devices that might cause it (of course there are many other reasons for it)
Doing this correlation is a lot more complex in virtualized environments with overlays and tunnels, where the user usually experience the problem in the logical network where in fact in many cases its in the physical network.
One example of a problem that happens many times is MTU misconfiguration in the physical devices (MTU needs to be increased from the default 1500 when using overlays like VXLAN). Knowing the path between two VM’s that stopped communicating can help us pin point, by following the traffic, where exactly the misconfiguration is.
One could argue, that we can potentially achieve this, if all the possible devices we can put in our data center, are connected to the controller and expose all the needed API’s between them to find the device neighbours.
Rather its feasible or not in real production with multi vendor devices, is a question for the future, but it certainly not a reality in many of today’s solutions and deployments (for example VMware NSX which is currently still agnostic to the physical switches/routers, although efforts are made for some synchronization between physical devices and the controller, but nothing related to topology discovery at least as much as i know..)
Lets start describing the currently feasible solutions to solve this challenge.
LLDP / CDP (SNMP)
CDP and LLDP are standard protocols to exchange neighbour discovery messages between network devices and are largely implemented in switches and routers (CDP for Cisco and LLDP for the rest). The neighbour information is accessible using SNMP MIB’s (reading the neighbours of each device).
Potentially this could be the perfect solution, but it has some major problems:
1) SNMP is many times disabled in production due to security reasons, even in cases when its enabled, LLDP and CDP are disabled for the same reason
2) Anyone that worked enough time with SNMP knows its the wild wild west, even that LLDP and CDP are standards, still many vendors choose to implement them in different and challenging ways which makes it hard to create a unified system to extract this information from the MIB
3) Some vendors have limitations in their LLDP implementation (for example Brocade switches connected with ISL dont support LLDP). this makes it hard to be a perfect solution in all deployments.
Hypervisor Agents and Traceroute
Traceroute is a tool meant to accomplish the exact thing we are trying to achieve, trace the path between two end points. (listing all the L3 devices on the path)
Traceroute does that by sending packets from source to destination with increasing TTL starting at 1, It leverage the fact that routers decrement packets TTL value by 1 when routing and discard packets whose TTL value has reached zero, returning the ICMP error message ICMP Time Exceeded to the sender.
We could potentially have agents in the hosts that sends traceroute to one another in order to find the path between two hosts. The major problem here relates to something i wrote in the beginning of the post, traceroute doesn’t work in multi paths / load balanced paths, it doesnt find all the paths and can even lead to finding invalid paths.
The following picture illustrate the problem of traceroute in multipath environments:
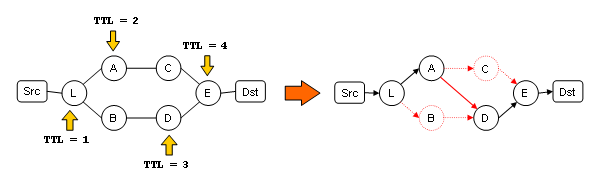
As you can see point L is a load balancer, the first packet with TTL=1 and the second packet with TTL=2 are load balanced to the upper path (starting at Device A), how ever the third packet with TTL=3 is load balanced to the down path (starting at Device B) This makes traceroute return invalid path as a result.
Paris Traceroute is an open source project that tries to solve the above problem.
Its key innovation is to control the probe packet header fields in a manner that allows all probes towards a destination to follow the same path in the presence of per-flow load balancing. It also allows a user to distinguish between the presence of per-flow load balancing and per-packet load balancing
you can read more about it in the link, bare in mind that it still doesnt solve all possible dynamic load balancing scenarios but still do better than classical traceroute.
Another problem of traceroute is that unlike CDP/LLDP it doesnt return the actual interface indexes that the devices are connected by, which is an important information when doing root cause analysis.
Record Route
Record route is an IP header option (option 7) and is used to track the path of the packet, every router in the path that see this option enabled must add its address to a route list.
When the packet is received in the end hop, the agent can extract the full path the packet traversed. Of course the same problem with multipathing exists with this solution just as well, in addition to possible security issues and even small performance decrease.
Flow Export
Flow export mechanism (NetFlow / IPFIX / sFlow) can help us collect and analyze flows statistics from all devices and potentially build topology graphs from it. A good post that is presenting a demo of troubleshooting a network path using this method can be found here.
The demo as you see is a very simple scenario, i am not sure what happens in real deployments when we have so many flows to analyze with duplicated inner IP’s.
Tags: OAM · ParisTraceRoute · SDN · SNMP ← Previous Post: NFV Acceleration (Part 1) Next Post: NFV Acceleration (Part 2) →