
Pluggable Distributed DB in OVN and Dragonflow
03 Aug 2015If you have been following my posts, i have written few deep dive and high level posts regarding OVN. OVN like similar other projects (Midonet, future Dragonflow) takes a different approach of implementing SDN control plane. Instead of using logically centralized SDN controller, OVN has distributed local controllers which exists at each compute host in the setup. These controllers all synchronize with each other using a distributed DB solution (OVSDB) which consist of data representing the cloud management system configuration (the logically desired state of the networks as configured by the tenants) and data inserted by the controllers themselves regarding their runtime state.
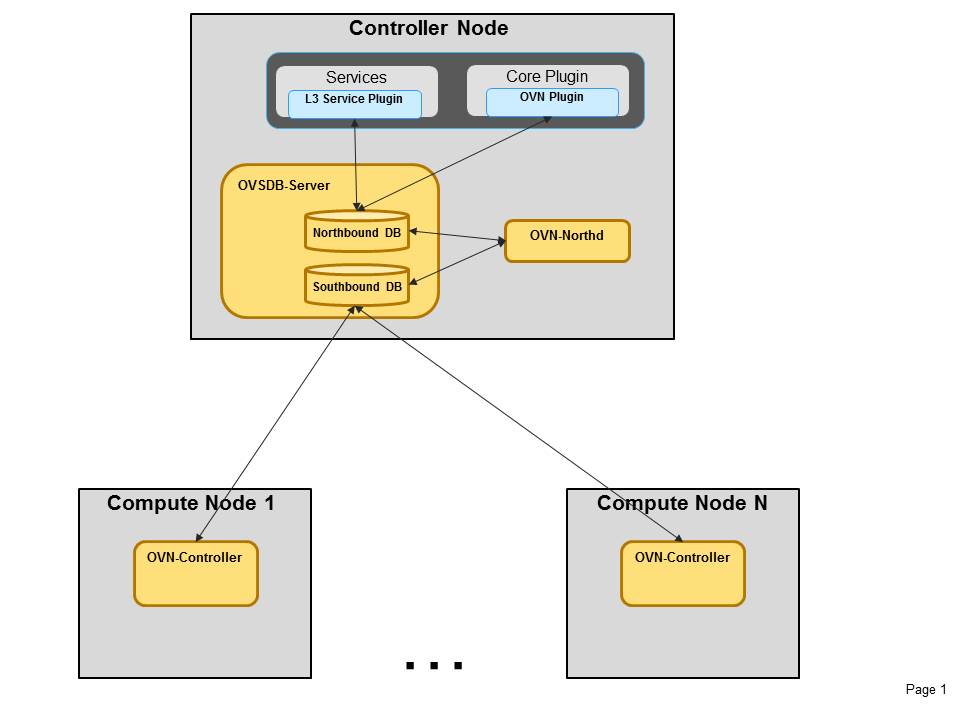
I will not dwell on the pros and cons of this approach in this post, but will try to describe the overall architecture and possible future enhancements. You can read more about a comparsion between these two approaches in Eran Gampel’s new blog post
OVN, uses a protocol called OVSDB (Open vSwitch Database), which is an open protocol defined in RFC 7047 and has been used up until now as a management protocol to configure OVS. If you are not familiar with OVSDB there are some great resources explaning it, you should check this post describing the basics of the protocol and then read this post by Brent Salisbury.. and this post by Matt Oswalt.
OVN leverage ovsdb-server (which up until now was only used locally to store the vswitch configuration) as the mechanism to distribute OVN DB across all the controllers in our environment. (It currently uses a single instance of ovsdb-server for both DB schemas: Northbound and Southbound)
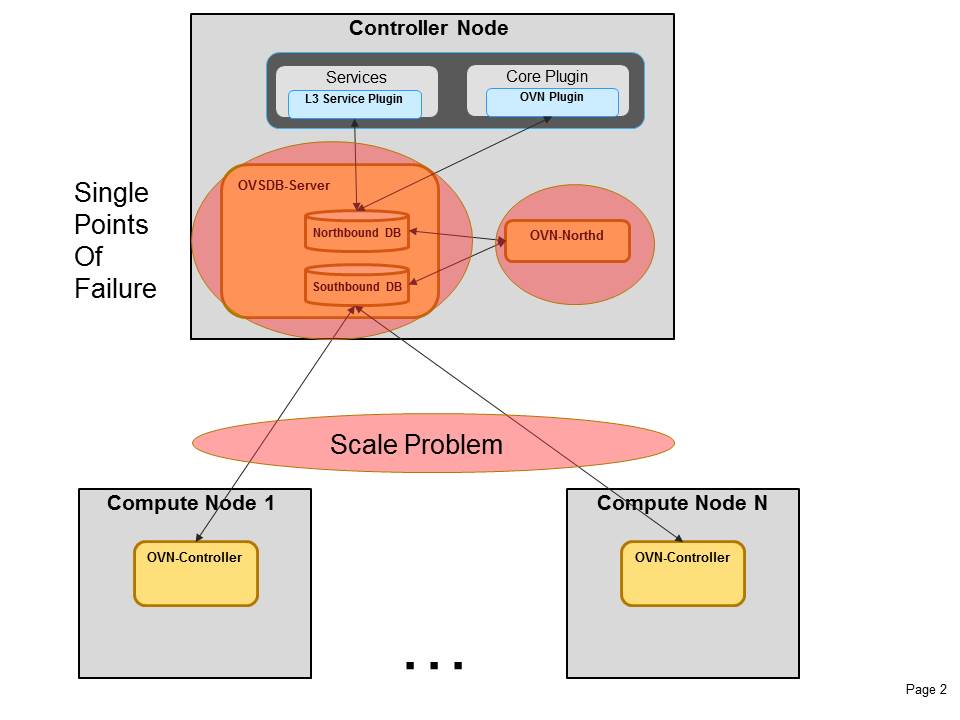
There are few limitations to this approach
HA / Redundancy
ovsdb-server is not distributed, which means you cannot have a cluster or redundancy/high availability to your instance which has a critical job in the process.
Scale
since ovsdb-server is not distributed it also does not support load sharing, this means that all controllers connect to the same instance and hence can introduce bottlenecks on busy setups, this doesn’t scale up well.
Different environments might have different requirements
Different users might need different solutions for DB distribution in regards to latency / configuration changes / resource availability to run the control plane software / SLA regarding configuration loses and so on, this approach means that ovsdb-implementation must support all possible use cases.
Locked-In Solution
User/Cloud admin is locked to a single solution implementation which is not necessary related to network virtualization
Opensource Alternatives
The distributed DB world is full of working solutions for all kind of needs, solutions that were tested and deployed for some time and can be re-used for this use case (maybe with additional tweaks)
In my opinion there are too many examples recently of projects that are trying to solve every possible problem out there, and all try to do this from scratch. (especially in regards to SDN/NFV areas).
If we look at open source software, i think that one of the guidelines should be reusability and project focus. The area of distributed DB is an area that is well explored with many well tested solutions (and many new coming soon) from people that focus on solving the problem of distributing your data across nodes for many different use cases.
OVN, and Dragonflow and all other projects in the area of SDN should focus on network virtualization and network services and not try to re-implement parts that could be taken from elsewhere. (and it doesn’t matter that they are key component in the overall solution) This in my humble opinion the true power of abstraction and the correct separation of project scope.
How can OVN or Dragonflow leverage this concept? the idea we propose is to make the distributed DB layer in all these solutions pluggable. What this mean is that the behaviour and features expected from the distributed DB framework should be abstracted to a set of API which can then be implemented by different plugins for different distributed DB solutions. (A very similar concept to how Neutron API can be implemented by various plugins, but as i will soon show a lot simpler)
The following diagram depicts what we have in mind and are currently implementing in Dragonflow:
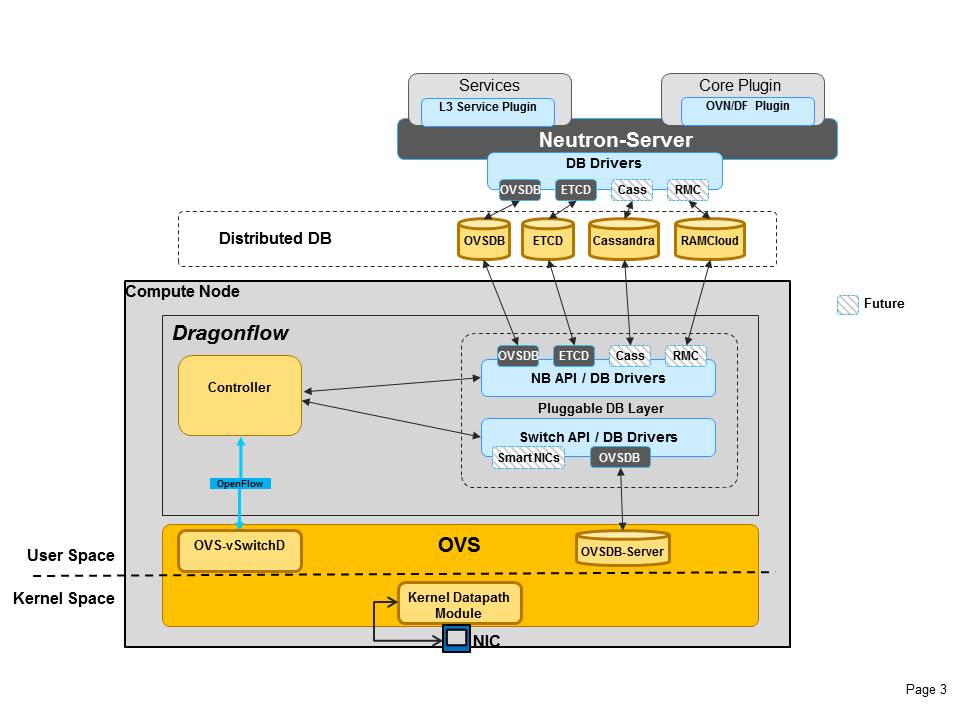
From the picture we can see that the local controller communicates with two different kinds of API’s the NB API (which is a common term for the distributed logically centralized DB solution) and the SB API which is actually the vSwitch configuration mechanism (in our case OVSDB).
The API can then be plugged to different implementations in our example: OVSDB, ETCD, Cassandra, RAMCloud, but there could be much more like Project Voldemort, ,Hazelcast, Redis, RethinkDB and also proprietary solutions.
Defining the API is not such a simple task, we want to be sure to abstract any feature/enhancement that the distributed DB layer can provide us, for example: transactions support, local cache, DB references between tables, publish-subscriber ability, consistency/locking and so on… But we don’t want the API to limit the possible solutions and how they should operate.
This led us to the conclusion that the API needs to be more on the applicative side and if needed can introduce base implementations for various types of distributed DB’s “families”. We will have a hierarchy similar to “inheritance” in order to simplify the process of creating a new distributed db solution plugin and for inserting new features. In next posts we can explore the API and understand more how we did it, but we found that if the model schema is well defined adjusting the applicative API to a new solution is rather simple.
The downside of using an applicative API is that introducing new features and changes in the DB model might require the various db plugins to be changed, we hope to reduce that to a minimum with our inheritance like model.
On the SB API you can see we also have a “Smart NICs” box, we plan to integrate Dragonflow with various common offload techniques that can help it offload some of the flows computation and classification into smart NICs or hardware, and synchronize the pipeline so features that are not applicable in hardware will be done in the software openvswitch. More on that as well in next posts.. interesting times are coming…
Tags: DB · Dragonflow · OVN · OVS · Openflow · Openstack ← Previous Post: OVN L2 Deep Dive Next Post: Kuryr - Bringing Containers Networking to OpenStack Neutron →