
Neutron DB Consistency
14 Feb 2016In this post i am going to describe some of the challenges of writing a plugin and a solution to Neutron and what problems we encounter when designing Dragonflow, problems that exists for all the other plugins just as well, like the reference architecture, ODL, OVN and such.
I will try to focus on the solutions we picked for Dragonflow but will also describe some of the alternatives we saw on other plugins. I believe that when picking a Neutron backend, these issues are very important and needs to be considered in order to meet scale and production readiness.
DB Consistency Problem
This problem is shared between all the different solutions, both the centralized SDN controllers like OpenDayLight, ONOS and BigSwitch and for the distributed control plane solutions like Dragonflow, OVN and Midonet.
How to make sure that the backend DB/view of the world is fully synced and consistent with the Neutron SQL DB.
What is the problem
The following diagram depicts a common deployment model for Neutron where we have few Neutron API servers all processing calls and using an SQL clustering solution like Galera for the Neutron DB. In the other side is the Neutron backend, the Neutron plugin for the backend is usually just a compiler that translate Neutron APIs to the backend data model (either using REST API or other DB protocol).
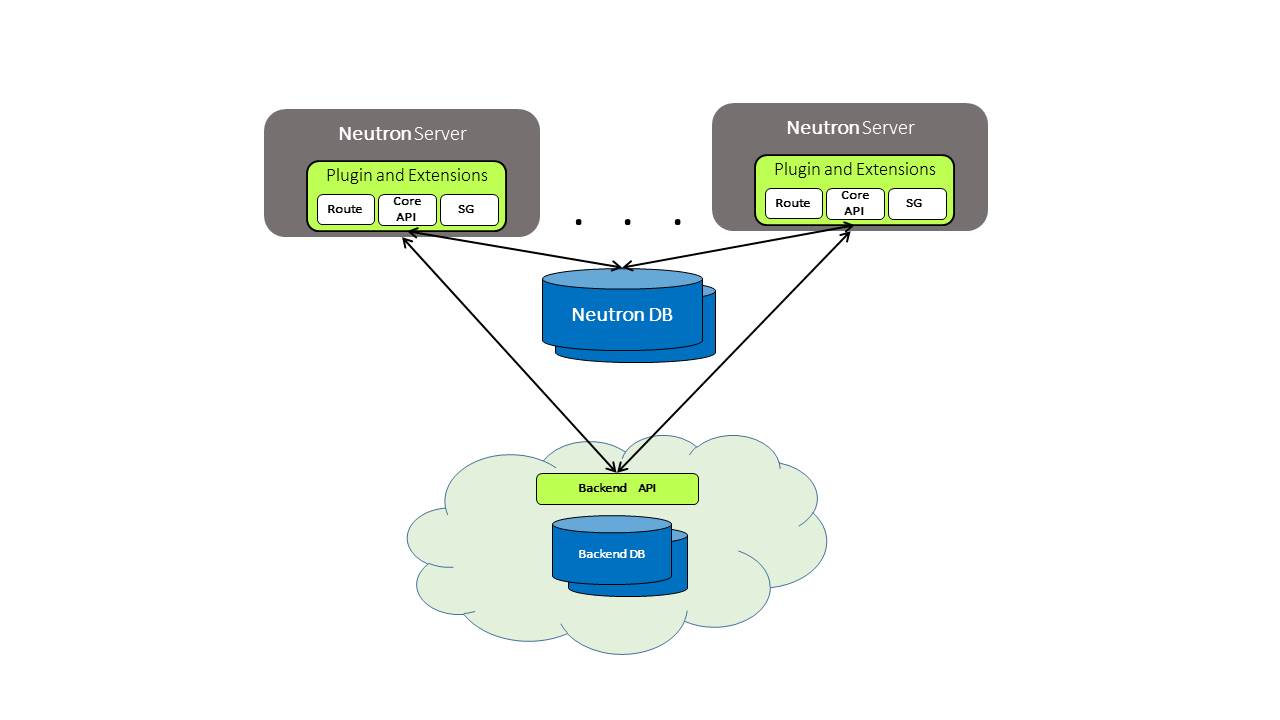
There are many scenarios that can lead to inconsistencies in the two DB’s, the Neutron one and the backend one, imagine the following scenarios:
Race Condition between the API servers
Imagine that two Neutron API servers update the same entity, only one of these updates is written to the Neutron SQL DB (the last one), however there is no guarantee which one was actually written to the backend last.
Backend DB Failures
Neutron writes transactions to the SQL DB involving updates/creates/deletes of few entities. First, there are a lot of backends that don’t support transactions and even when they do you dont really want to block Neutron DB operations waiting for the backend results.
What happens when the backend fails or timeouts ? rollbacks can fail too, what you do in case of failures and so on..
Failures of Neutron Servers or Backend DB Servers
In production things can and will get bad, your API servers or backend DB could crash and they could do so in the middle of a process, how you make sure to sync between the two “worlds” when everything comes up again ?
This is also relevant in the more “standard” use case of updating versions and switching between backends or even just a regular restart.
Possible Solutions
The following solutions were considered until we decided on the final one which was picked due to the extra requirement to also solve the publish-subscribe problem mentioned below.
Global Lock using Neutron SQL DB
Serializing all writes both to the Neutron DB and to the Dragonflow DB under the same global lock while performing full sync in case of a problem or on restart.
This solution is kind of restricting performance wise and doesnt help us with the publish-subscribe, of course its also limiting when thinking about status updates happening from the compute nodes.
DB Journal
This is a common solution to such problems, write every Neutron DB operation also to another global table in Neutron SQL called the journal, include the key, value and operation type (create/update/delete).
Then have a separate thread that reads this table and apply the operations to the backend DB.
Unlike the first solution this doesnt block the Neutron operation, but it requires the same objects to be in the DB twice and it also doesnt help us for the publish-subscribe. Another caveat here is we need to make sure the syncing Thread is up and running.
Dragonflow Solution
The solution we picked is to create another table in the Neutron DB, this table has the Neutron object id, a version number of this object and its type.
The versions are also written to the Dragonflow DB and what we use to update the Dragonflow DB with is a compare and swap operation. (We added the requirement that any DB that wants to work with Dragonflow must also have compare and swap operation, which is available for most key-value DBs)
Whenever we update Dragonflow DB we use compare and swap which also should have the previous version. If the operation failed it could be for few reasons:
1) We read the object from DF DB and find out that the current version is newer than the one we have, we can discard the update
2) The version is older, we need to re-try.
The good thing about this solution is that it is useful for the publish-subscribe use case described below and it also doesnt block the Neutron DB operations.
This solution also makes the “full sync” process simpler. If we want to run periodic checks or even perform full sync on every failure all we need to do is iterate and compare the versions between the Neutron table we have and the versions we have in the Dragonflow DB.
Publisher-Subscribers Consistency
Consistency between the two DB’s is one problem, but most solutions also have an agent in all the compute nodes that receive the DB changes in a publish-subscriber mechanism and apply them locally. (Centralized controllers still have to make sure that the virtual switch received all the OpenFlow messages and has the correct pipeline configured based on recent DB updates)
The following diagram depicts this scenario:
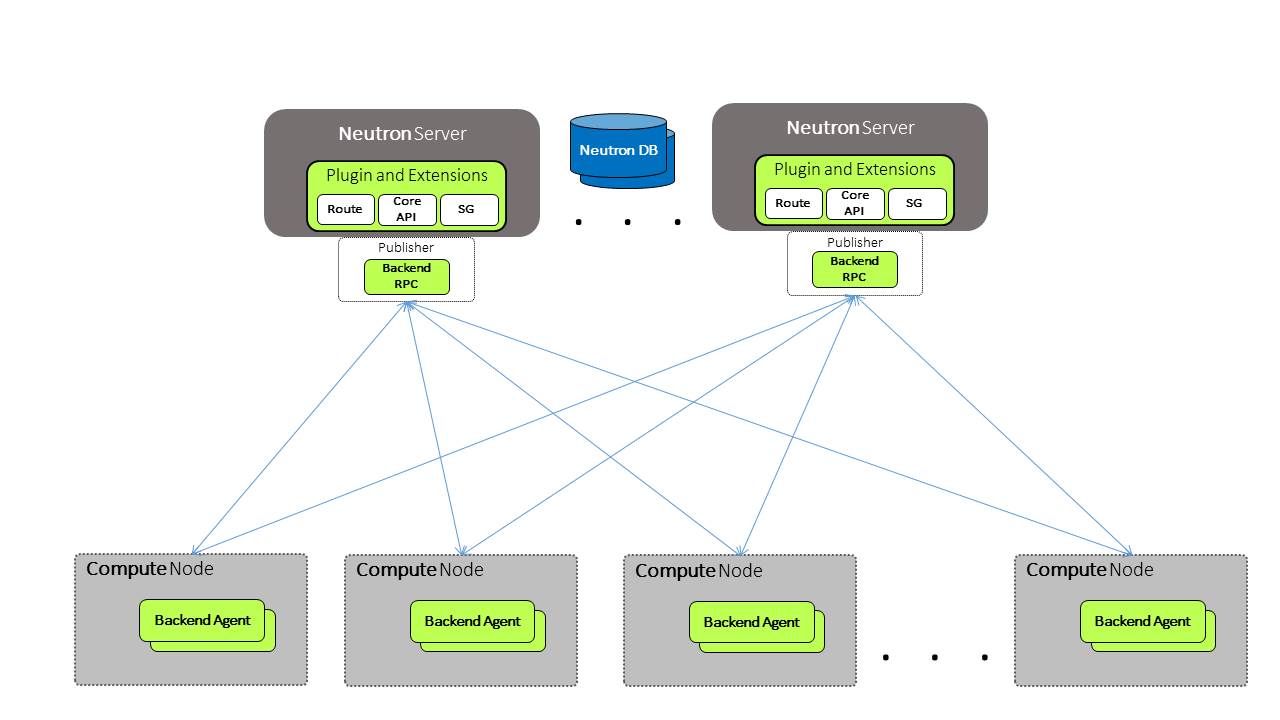
The Problems
Race Condition
Same as in the DBs case above, the agent could receive two updates for the same object but apply them in the wrong order, not reflecting the state that is actually saved in the Neutron DB.
Losing Notifications
Reliability is a big issue in publisher-subscriber systems, we need to make sure no notifications are lost.
Startup Sync
When a subscriber start, it needs to receive all the data it needs, this process can trigger high volume of notifications. imagine what happens when more then one subscriber needs this concurrently…
Dragonflow Solution
On every update we now get the version number of the object, we can compare it with our local cache and update newer versions. This solves the race condition.
We also had an idea to only send the id of the object that changes without the value and let the client (the local controller in the compute node) read the value from the DB and apply it, this reduce the load on the publish-subscribe mechanism (especially on the publisher side as it now needs to send smaller messages).
With the version sent we can also verify that what we read from the DB is actually the most updated version (given that key-value stores are not always evenly consistent)
The other problem we need to solve is the reliability, making sure the local controller doesnt lose any notifications (regardless of the reliability mechanism the publish-subscribe uses or doesnt support - for example ZeroMQ doesnt support reliable publish-subscribe mode)
What we plan to do here is have a counter of the messages sent by every publisher and have the subscribers (local controllers) read this counter every X time to make sure they didn’t lose any events.
They will sum it up and make sure they received all messages depending on when they started, this mean we will need to read these counters to know the starting point when the controller goes up before subscribing to events. In case of inconsistency, this node will be synced with all the information.
Its important to note that since we use a distributed DB solution the sync which happens on inconsistencies and on restart uses DB client operations to fetch the data from a cluster of key-value DB servers, approach that is more efficient then requesting all updates from a publisher.
Summary
I hope i managed to share the difficulties and challenges that evey Neutron solution is facing and that i have managed to share the importance of looking and understanding how and if the specific solution you use solve these challenges.
Tags: DB · Dragonflow · Neutron · OVN · Openstack · SDN ← Previous Post: Kuryr Support for Docker Pluggable IPAM Next Post: Kuryr and Neutron Existing Resources →