
Dragonflow Security Groups At Scale
28 Dec 2015In this post i want to present to you some of our ideas for implementing security groups in Dragonflow. This is actually still in design process (where some parts that are needed anyway are already being coded) but i think it shows the strength and possibilities of Dragonflow syncing policy level abstraction to the local controllers, which allow us to solve interesting problems at scale.
We approached this problem receiving great feedback from the team that deploys OpenStack in a big cloud environment and understanding the bottlenecks for security groups at scale in the current Neutron implementation. (At least the problems we noticed with our configurations)
The Problems
Data plane performance
Its important to note that Security groups are stateful — responses to allowed ingress traffic are allowed to flow out regardless of egress rules, and vice versa. Current Neutron implementation adds a linux bridge in the path between each port (VM) and OVS bridge.
This linux bridge is configured with IP table rules that implement security groups for this port. (This was done as iptables couldn’t be configured on OVS ports)
The following diagram demonstrate how the data path looks like:
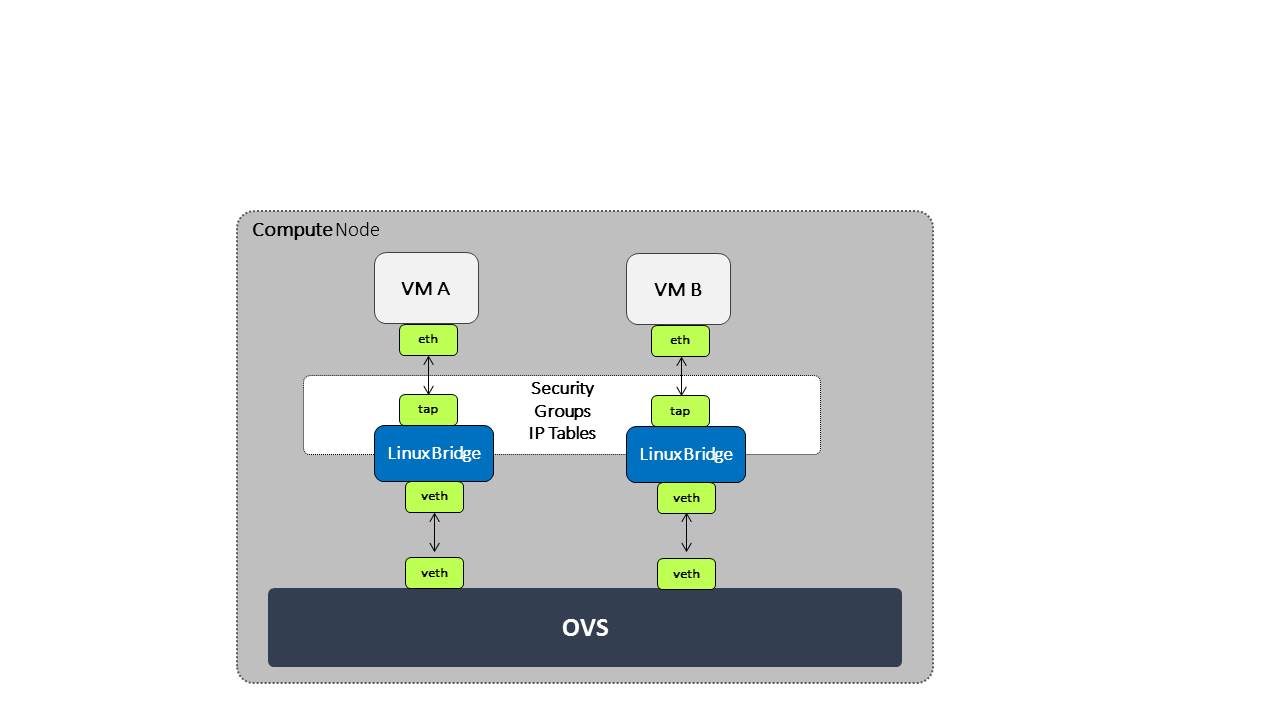
In Dragonflow we are already connecting the VMs to the OVS bridge directly. We plan to leverage OVS connection tracking integration, with it we will implement all security group rules using OVS flows and actions with minimum usage of flows.
This approach is already considered in Neutron and already implemented in OVN, however i will describe here how we plan to keep the number of flows to minimum, one flow per one security group rule regardless of number of ports. This characteristic is important for the next problem and for managing and debuging our environment.
Control plane performance
In addition to the data path implementation described above, there are also RPC challenges for distributing the security group configuration to the local L2 agents, applying these changes and reacting as fast as possible.
In order to understand the problems at scale, its important to first understand security group feature capabilities.
A security rule applies either to inbound traffic (ingress) or outbound traffic (egress). You can grant access to a specific CIDR range, or to another security group.
When you add a security rule to group Y and set security group X as the source for that rule, this allows VM ports associated with the source security group X to access VM ports that are part of security group Y. (The reverse behaviour applies the same for destination)
The default security group is already populated with rules that allows VM ports in the group to access each other.
The above mentioned capability makes the current process of syncing security group information difficult because it needs to keep track of all the VM ports and the security group they belong to and make sure to sync this information on every change to the local agents.
More then that, changes in VM port configuration (addition/removal) and changes in security group rules/groups require a complicated process or re-compiling the rules to iptable chains pipeline and rules.(Something that sometimes require re-compilation of the entire pipeline) (In current implementation this is managed with ipsets to improve this problem).
Neutron reference implementation issue these security group changes using CLI iptables commands, which makes large updates slow at the L2 agent.
Even with flow based solutions, the problem still exists as the flows usually have matching fields for the VM ports in the group (either by id, or by L2/L3 headers and network id) in order to comply with the above requirement.
I will soon present how we avoid the need to update security group rules when updating VM ports (creation/deletion/update) and also show how we plan to have one flow per one security group rule.
All of this is achievable thanks to the fact we synchronize policy level abstraction of security group information to the local controllers.
Dragonflow Security Groups Implementation Design
Solution Guidelines
-
Leverage OVS connection tracking for implementing state full rules
-
Avoid the need to recompile or change flows for every VM port add/delete
-
Keep flow number that implement security groups to a minimum
-
Changes to security group rules will update minimum number of flows
Solution Steps Explained
1) Dragonflow will allocate a global/local id per security group (if locally at each compute node per security group), this is an increasing number.
2) On the ingress classification table (table 0) , Dragonflow sets reg6 to match the VM port security group id
3) On L2 lookup and L3 lookup tables, Dragonflow installs flows which set reg5 as the destination VM port security group id (at this point the destination VM port both for L2 or L3 is known - we are after distributed virtual routing step)
4) After classification, Dragonflow sends traffic to connection tracking table. We retrieve the connection state of this flow for IP and IPv6 traffic, The zone is the same as reg6 (src VM port security group id)
ip, actions=ct(table=<egress_security_group>,zone=NXM_NX_REG6[0..15])
ip6, actions=ct(table=<egress_security_group>,zone=NXM_NX_REG6[0..15])
5) In the first security table (egress) we first match if a connection tracking entry exists, if it does (with state EST) we move to the next table in the pipeline, if its invalid state we drop the packet and if the connection state is “NEW” we continue checking security rules for Egress
priority=65534,ct_state=-new-est+rel-inv+trk, actions=resubmit(,<next_table-egress>)
priority=65534,ct_state=-new+est-rel-inv+trk, actions=resubmit(,<next_table-egress>)
priority=65534,ct_state=+inv+trk, actions=drop
6) We then have rules that match for all local security group rules on the outbound side (Egress side - traffic leaving the local VM).
It is very easy to model these rules when we have both the source and destination VM ports security group ids identified.
On match we commit the flow to the connection tracking module with the same zone as the source VM port security group id.
For example, lets assume we have the following topology:
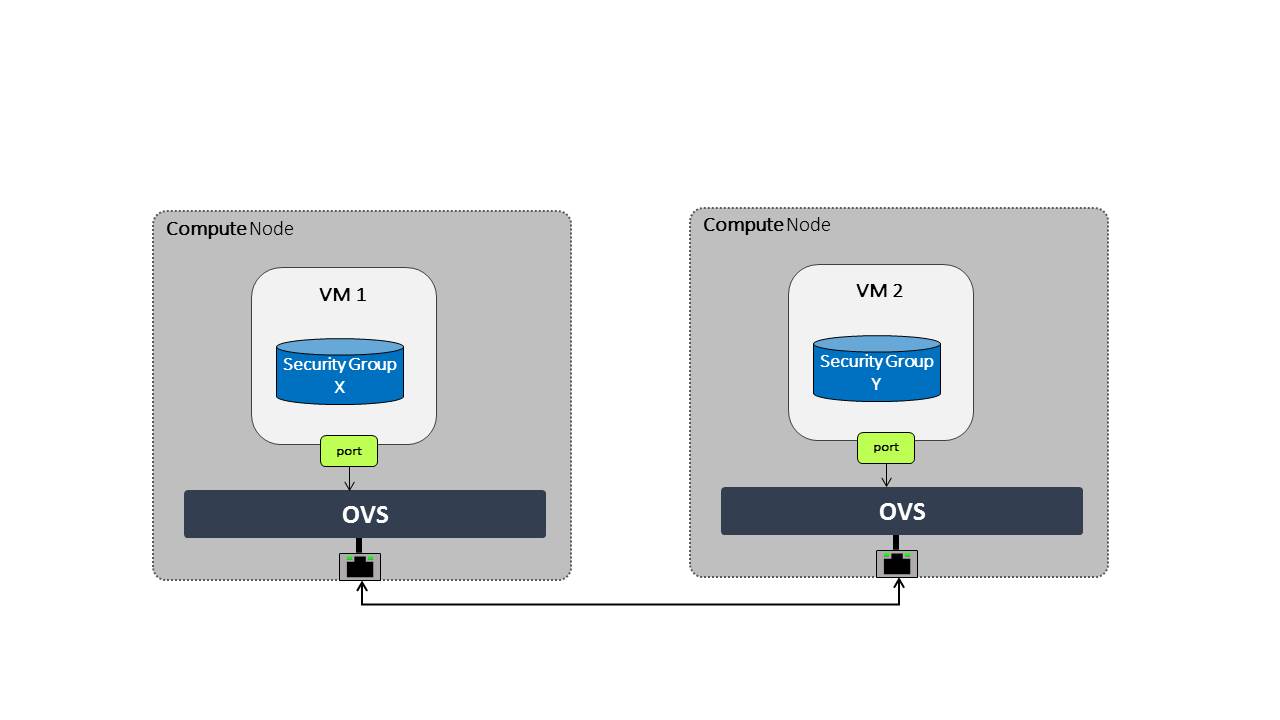
If security group X has the following rule
Direction:Egress, Type:IPv4, IP Protocol:TCP, Port Range:Any, Remote IP Prefix:0.0.0.0/0
This will translate to the following flow
match:ct_state=+new+trk,tcp,reg6=X actions=ct(commit,zone=NXM_NX_REG6[0..15]),resubmit(,<next_table>)
And its also very simple to model if we have the following rule
Direction:Egress, Type:IPv4, IP Protocol:TCP, Port Range:Any, Remote Security Group: Y
This will translate to the following flow
match:ct_state=+new+trk,tcp,reg6=X,reg5=Y, actions=ct(commit,zone=NXM_NX_REG6[0..15]),resubmit(,<next_table>)
With this approach we can model every security group rule to exactly one flow, and any changes in VM port additions/deletion/updates don’t have to change any of these flows just the classification rules for that port (which have to change anyway). (I have excluded network id classification which might be needed but left out for simplicity)
It is also very simple to delete/modify these flows in case of security rule update as each rule always only map to a single flow.
7) For both solutions, we need to install flows with lowest priority in the security group tables to make sure we drop any IPv4/IPv6 that didn’t match any of the rules
match:ip,reg7=0x4,reg5=X actions=drop
match:ipv6,reg7=0x4,reg5=X actions=drop
And resubmit any other traffic which is not IP to the next table.
At this point the two mentioned solutions differs from each other.
Solution 1 - Perform Full Security Inspection at Source
With this solution after the egress security group table (which classified rules for the local VMs egress policy) we have another table which holds the destination port ingress security group rules converted to flows.
The pipeline looks like this:
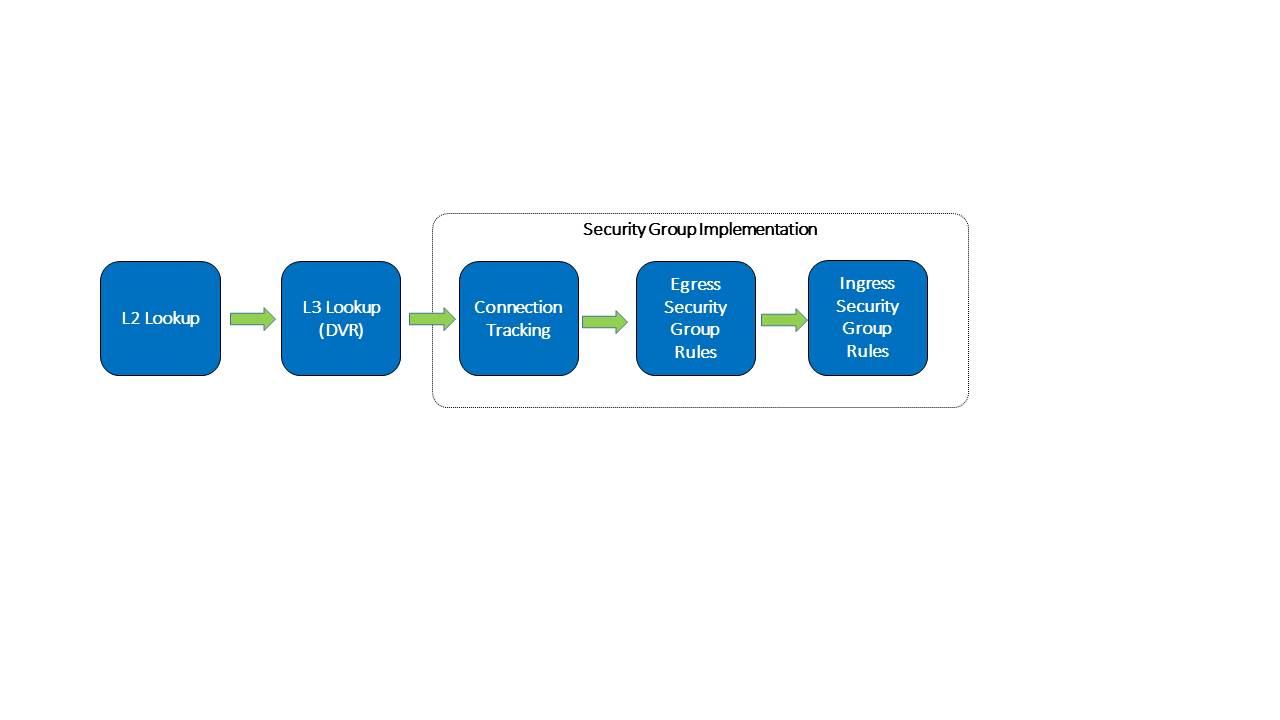
Converting security group rules to flows is very similar to the above process but now we use reg5 to indicate the current security group id we inspect and reg6 to mark the source port security group id. (Remember that reg5 holds the destination VM port security group id and reg6 holds the source VM port security group id)
Due to the state fullness of security groups we must also change table 0 which is receiving the traffic and dispatching it to the port at the destination compute node.
We need to make sure to commit this flow to connection tracking module at the destination, this will be used when the destination tries to reply. This is the only action we need to perform at destination as we already verified all security rules both for egress and ingress at the source.
Pros
-
We block traffic at the source and avoid sending traffic which will be dropped at the destination
-
We dont need to pass any additional metadata and hence dont need Geneve tunneling like the second solution
Cons
-
In this solution we have to install in the ingress security table flows that match all possible destination ports (still one flow per rule)
-
Its problematic if we are doing smart broadcast/multicast distribution as different security policy can be configured to ports in the same broadcast/multicast domain
-
This is problematic for traffic coming from public/external network (This is solvable, but i will not dwell on it in this post)
Solution 2 - Perform Ingress Security Inspection at Destination
This solution perform the ingress security group classification in the destination but in order to model security groups classification similar to the model i presented above, the destination also must know the source port security group id.
For this we use Geneve dynamic TLV and pass to the destination the source port security group id (in addition to the destination port id which is written in the tunnel VNI).
The pipeline for this solution looks like this:
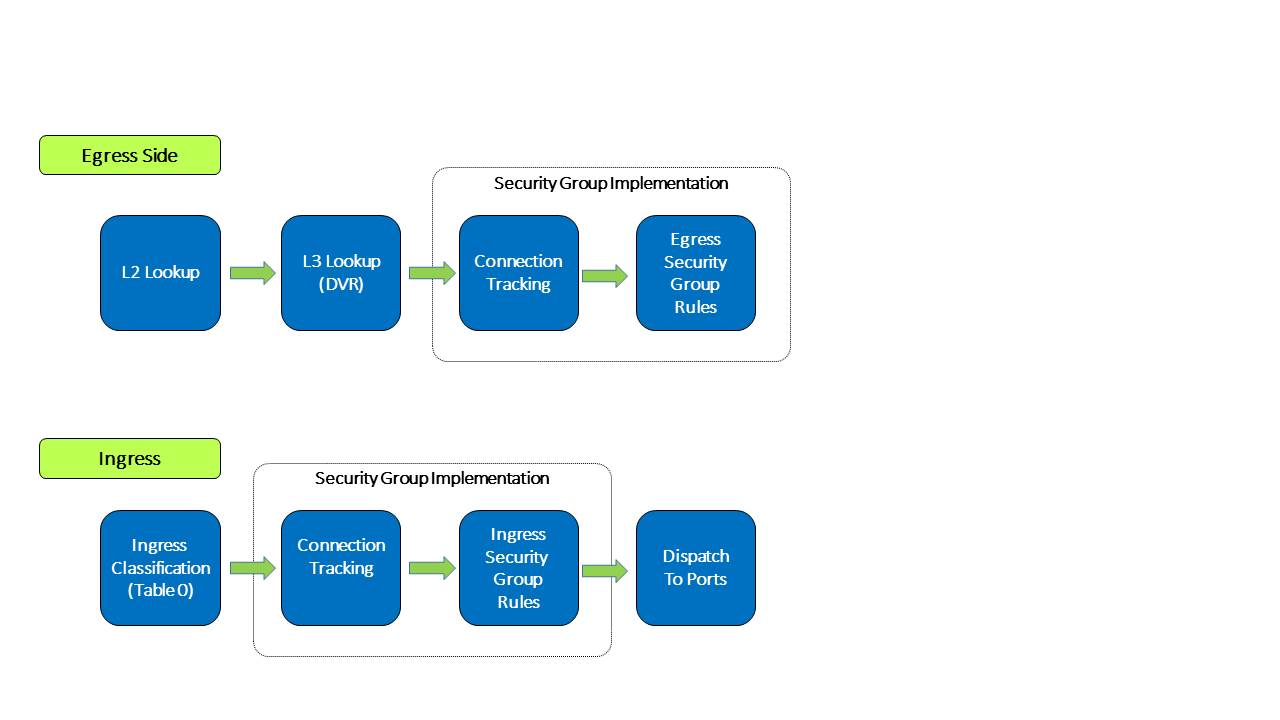
Pros
-
Easier to model public/external traffic security groups
-
Can work for optimized L2 broadcast/multicast traffic
-
Require installing security group rule flows only for local ports
Cons
-
We have to use Geneve (or other dynamic tunneling) in order to pass the source security group id number.
-
We send traffic to destination even when we can know it is going to be dropped
Summary
This design is still in review and we welcome any comments/ideas or problems you might find in it. You can comment on the spec review patch.
I think that security group is one place where performance degrades and creating a good solution is important. I believe that with the policy level abstraction data from the DB we can be flexible to create solutions like suggested here which makes management/debugging/reacting to changes better in addition to all the data plane optimizations.
Tags: DVR · Dragonflow · Neutron · OVS · Openstack · SDN ← Previous Post: OVN L3 Deep Dive Next Post: Kuryr Support for Docker Pluggable IPAM →